
Tracking Without Bells and Whistles
This article talks about a completely new paradigm of object tracker called Tracktor. And what’s special about this tracker is that it requires only an object detector and nothing else! No additional training or additional algorithm is required for tracking objects. Hence the name “tracking without bells and whistles”.
You can checkout the complete research paper at arXiv.org. This article gives an overview of the paper.
Tracking by detection
Tracking by detection is a paradigm of object tracking algorithm that use an object detector as a basis for performing object tracking. We are having a look at it because it is the predecessor to our Tracktor.
Modern Object detectors such as YOLO and FRCNN are able to achieve extremely high accuracy with very low computation time. The ideology behind tracking by detection is that since these object detectors are fast, we might as well use object detectors for performing tracking.
Tracking by detection can be essentially simplified to the following three steps:
-
Perform object detection on frame at time t.
-
Perform object detection on frame at time t+1
-
Map the objects detected in frame t to the objects detected in frame t+1
![]()
The third step is known as data association as it involves associating objects detected in one frame to that of another. There are various algorithms for performing data association. We can also use different types of object detectors for performing the object detection step. Object tracking algorithms like SORT and deepSORT use this paradigm of object tracking.
Revisiting Object Detector
In order to understand how this new object tracker “Tracktor” works, we need to go back to the basics and understand how single and multiple object detectors work.
Single Object Detector
In a CNN based object detector, we generally have a VGG backbone network which converts an image into feature maps. We stretch out these features maps into a fully connected layer. Then we can use the Fully Connected Layer to perform a classification based on class label and a regression for bounding boxes. You can read more about this on the internet.
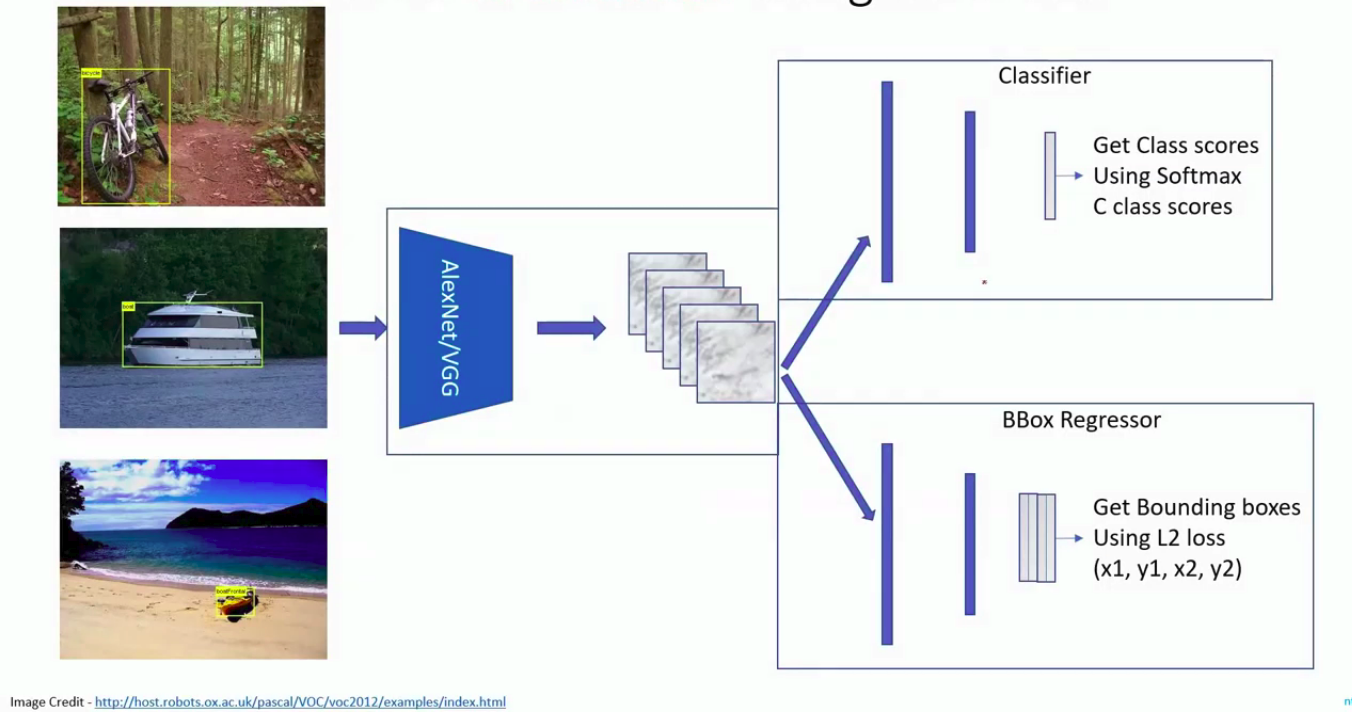
While testing, when you pass an image to object detector the output looks something like this:
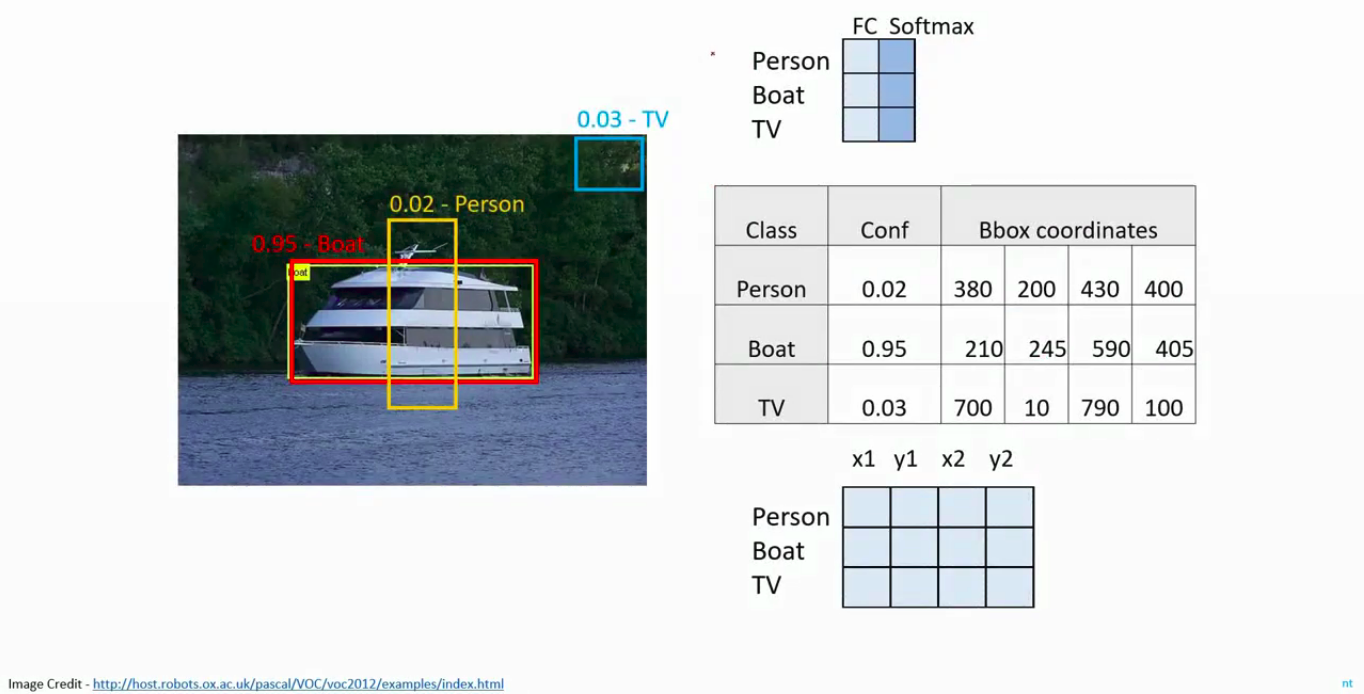
You get a list of bounding box coordinates and a class confidence score attached to it. We pick the one with the highest score as the output.
Multiple Object Detector
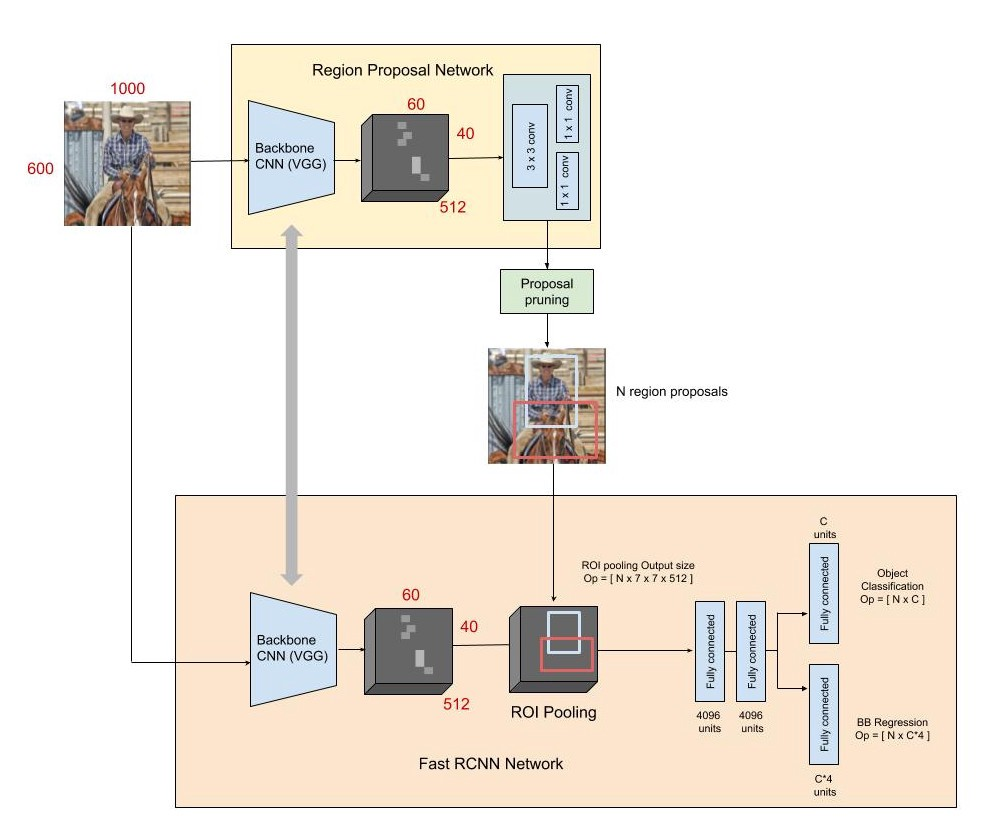
Now that we have seen how a single object detector works, let’s fast forward to multiple object detection. In this case, we will be looking at Faster RCNN.
An FRCNN is in some ways similar to a single object detector. One major addition is the presence of a Region Proposal Network, which proposes the regions where the likelihood of finding an object is extremely high. Once we get these regions from the RPN, we perform a pooling of the region of interests, and then apply single object detection on each of these regions. As usual, we convert it into a fully connected layer and perform a classification for class label and regression for the bounding boxes. Now, we get bounding boxes and class confidence scores for each region of interest and we pick the ones with highest score in each region of interest.
Introducing “Tracktor”
According to the paper, “Tracktor exploits the regression head of a detector to perform temporal re-alignment of object bounding boxes.” Let us try to understand what this exactly means. The below image shows a simplified version of tracktor.

At time t-1, we have the coordinates of the bounding box of the object given by bk{t-1}.
At time t, we assume that the object has moved slightly, as shown in the figure. Now, we pass this frame at time t to the FRCNN and pass the bounding box of the previous frame bk{t-1} as the region of interest.
We have seen how an object detector has a regression head which gives the coordinates of a tight bounding box around the object and a confidence score associated with it. When we pass the bounding box of the previous frame as ROI and the current frame as input image to FRCNN, the regression head will automatically find a new bounding box that tightly fits aroung the object (which has slightly moved), giving us the new location of the object.
Hence, it has been termed as temporal realignment. We are using the regression head to realign the bounding box obtained at time t-1 to find the object at time t.
Drawbacks of Tracktor
We can clearly see some of the major drawbacks:
-
Our assumption that an object moves only slightly between two consecutive frames may not always hold. For example, in the previous example, if the man was moving extremely fast and there was a large distance between his position at
t-1and att, then a realignment would fail. The realignment works only because they move slightly between the two frames. -
In order to make sure that the objects only move slightly between two consecutive frames, we need a really high frame rate, which might not always be possible.
-
Large camera motion will also hamper the obejct tracking because the object would move by a large amount between two consecutive frames.
Ways to fix the drawbacks
-
For a fast moving object, we can use a linear velocity model to predict it’s location in the future timeframe and then use it to perform temporal realignment. This will definitely perform better than a simple realignment.
-
Camera motion compensation algorithms can be used to avoid problems caused by large camera motions.
Tracker Re-identification
In any object tracker, if an object cannot be detected in the next frame, the object is assumed to have left the scene and the tracker is killed. The tracker re-identification makes provision for re-identifying dead trackers/objects if they reappear in future frames.
Instead of removing dead trackers, they are kept alive for a certain number of frames FReID. If a new object is deteced in the future, a siamese neural network is used to find the similarity between the dead object and the new one. If they are similar, then the tracker is revived and it starts to track the object again.
It also uses motion model and IOU (intersection over union) to minimize false re-identifications.
Tracktor combined with Motion Model and Re-Identification forms Tracktor++.
Observation
The plot below shows the percentage of object tracking for varying object visibility.
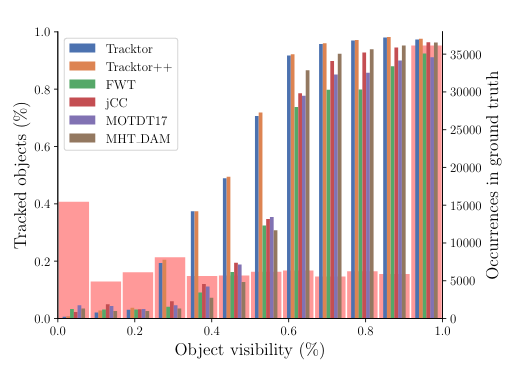
As we can see, when the object visiblity is low, almost all the object trackers perform poorly. As the visibility starts to increase, we can see a drastic improvement in the performance of Tracktor and Tracktor++ as compared to other object trackers. They have an edge over other object trackers. But when the object visibility becomes very high, almost all the trackers perform well again.
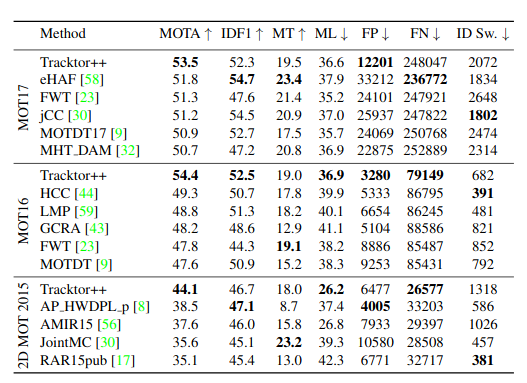
The above table shows the benchmarks scores of Tracktor compared with various other object tracker. We can see that Tracktor performs really well and the best part is that tracktor uses nothing but an object detector. There is no extra step like data association which happens in many trackers.
Conclusion
Tracktor is a new paradigm of object tracker than performs tracking only by using the object detector. The speciality of tracktor is that it does not require any other sort of algorithm or trained model to perform tracking and needs just a simple object detector.
It is also able to perform really well when compared with other trackers. It has several extensions which can further improve the capabilities of Tracktor, making it even better. Considering that this is a fairly new paradigm of tracking, it has a lot of scope for improvement in the future.